

Stack چیست؟
در اوایل دوران شکوفایی رایانه، صرفاً یک مجموعۀ متوالی از دستورات وارد پردازنده میشد و تا دستور قبلی پردازش نمیشد، دستور بعدی اجرا نمیشد. هر دستور میتواند با بخشی از دادۀ درون حافظه کار کند؛ میتواند دادهای ایجاد کند، آن را بخواند، و در زمانی که دیگر نیازی به آن نداشت آن را نابود کند. برای مثال فرض کنید یک متغیر با نام x درون حافظه داریم و میخواهیم مقدار این متغیر را چاپ کنیم. ابتدا قسمتی از حافظه را به این متغیر اختصاص میدهیم، سپس مقدار مورد نظرمان (مثلا عدد 100) را در آن قسمت از حافظه مینویسیم، و آنگاه آن را چاپ میکنیم. وقتی هم کارمان با آن تمام شد، آن قسمت از حافظه را آزاد میکنیم تا متغیری دیگر بتواند به جای آن بنشیند و دستوری دیگر بتواند بر روی آن بخش از حافظه کار کند.
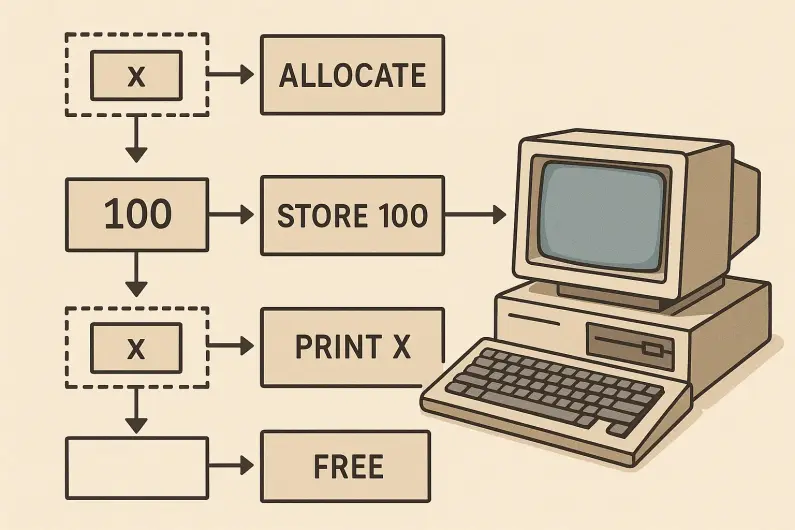
برایناساس در مرحلۀ تخصیص حافظه، از آنجا که میدانیم چه مقداری را درون آن خواهیم ریخت، میدانیم آن مقدار چقدر از حافظه را درگیر میکند و لذا به همان میزان، تخصیص حافظه را انجام میدهیم. مثلا اگر نیاز باشد عدد 100 را وارد حافظه کنیم، کافی است 7 بیت از حافظه را جدا کنیم و عدد 100 را در آن بنویسیم. یا مثلا عدد 255 به میزان 8 بیت را درگیر میکند.
این دادههایی که در طی دستورات پشتسرهم ایجاد میشوند و همچنین مقدارشان و حجمشان از ابتدا مشخص است، در فضایی از حافظه قرار میگیرند با عنوان Stack یا پشته.
ویژگیهای Stack
در نتیجه Stack چند ویژگی دارد:
- حجم هر متغیری که درون آن قرار میگیرد، در همان هنگام تخصیص حافظه مشخص است؛ مثلاً یک دادۀ 8 بیتی، سپس 16 بیت، سپس 8 بیتی، سپس 128 بیتی و …
- دقیقاً مشخص است که دادۀ هر متغیری در کدام بلوک از Stack قرار دارد و لذا به سادگی و با سرعت بالا میتوان به آن دسترسی پیدا کرد.
- امنیت آن کامل است و هیچکس از بیرون نمیتواند تغییری ناخواسته درون آن ایجاد کند؛ لذا وقتی با دستوری متغیری را تعریف کردیم و برای آن تخصیص حافظه انجام دادیم، مطمئنیم که خودمان هستیم که در ادامه از آن استفاده خواهیم کرد و وقتی دیگری به آن متغیر نیازی نداشتیم، نابودش خواهیم کرد؛ چراکه ترتیب کار با هر بلوک از حافظه، کاملا مشخص است.
اما اگر پشتسرهم نباشند یا حجمشان از ابتدا مشخص نباشد، مشکلاتی ایجاد میشود.
- کاربرد اصلی Stack در دو جا است؛ یکی متغیرهای محلی درون توابع (که این متغیرها با اتمام تابع بهصورت خودکار نابود میشوند)، و یکی در هنگامی که یک تابع، تابع دیگر را فراخوانی میکند و متغیری را به عنوان آرگومان برای آن میفرستد. کاربردهای جزئی دیگری هم دارد که از آن صرف نظر میکنیم (مثل متادیتای تابعی که فراخوانی میشود و موارد دیگری که کنترل آن بر عهدۀ کامپایلر است و استفادۀ داخلی برای کامپایلر یا JVM یا موارد مشابه دارد).
- مکانیزم Stack، اولین چیزی است که برای مدیریت حافظه به ذهن میآید. طبیعتاً اگر کسی بخواهد در ابتدای امر با حافظه کار کند، روش Stack به ذهنش میرسد و گویا یک راهکار بسیار استاندارد برای مدیریت حافظه است. اما برای شرایط پیچیدهتر ممکن است Stack نتواند نیازهای ما را برآورده کند.
محدودیتهای Stack
حال دو فرض زیر را انجام دهید.
1- فرض کنید که حجم متغیر از ابتدا مشخص نباشد؛ در این حالت معلوم نیست که چقدر باید حافظه اختصاص داده شود و ممکن است کمتر از حد مورد نیاز، یا بسیار بیشتر از حد مورد نیاز، تخصیص حافظه صورت بگیرد که اولی موجب خطا در برنامه میشود و دومی موجب هدررفت حافظه. همچنین ممکن است به میزان مورد نیاز، یک جای مشخص در حافظه نباشد، بلکه مجبور باشیم در میانۀ دادههای دیگر، دادۀ خود را جا کنیم.
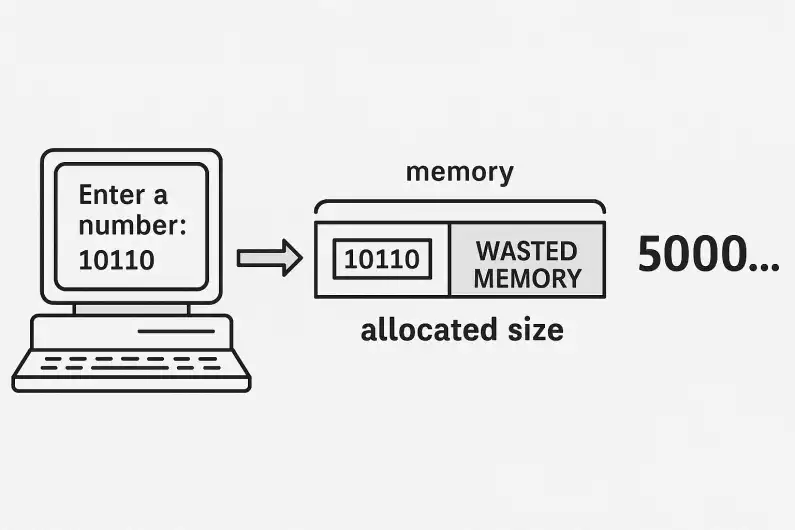
بهعنوانمثال در نظر بگیرید که یک عدد از کاربر دریافت میکنید که حجم آن در هنگام نوشتن برنامه برای ما مشخص نیست. اگر کاربر صرفا یک عدد 5 رقمی (باینری) وارد کند، شما میتوانید به اندازۀ 5 رقم در حافظه تخصیص فضا انجام دهید. اما اگر 5000 رقم وارد کرد چه؟! شما که نمیتوانید از ابتدا جا برای 5000 رقم باز کنید چون شاید کاربر 5000 رقم وارد کند! اگر کاربر 5 رقم وارد کرده باشد، شما به اندازۀ 4995 رقم را در حافظه هدر دادهاید.
هر راهکاری که برای این مشکل مطرح کنید (همچون تکهتکه کردن داده، تغییر اندازۀ بلوک و…)، مختص به جایی خواهد بود که واقعاً حجم دادۀ ورودی مشخص نباشد. اما در جایی که نیاز به متغیرهای محلی و متغیرهای کنترلی ساده داریم، این راهکارها نهتنها دردی را دوا نمیکنند، بلکه موجب کاهش کارایی برنامه میشوند. در نتیجه لازم است سازوکار جداگانهای برای دادههای نامعلوم فراهم شود.
2- فرض کنید دستورات پشت سر هم نباشند، بلکه چند رشتۀ پردازشی سعی کنند به صورت همزمان به یک دادۀ موجود در حافظه دسترسی پیدا کنند و یکی بخواهد در آن بنویسد و دیگری بخواهد آن را بخواند! طبیعتا رشتۀ خواننده توقع ندارد مقدار موجود در آن قسمت از حافظه تغییری کرده باشد که او از آن خبر ندارد. یا ممکن است دو رشته بخواهند به صورت همزمان در یک بخش از حافظه بنویسند و این نیز موجب رقابت میان آنها میشود. حتی ممکن است یکی بخشی از حافظه را تخصیص بدهد و رشتۀ دیگر بخواهد در آن قسمت بنویسد، اما این رخداد به صورت معکوس اجرا شود؛ یعنی قبل از اینکه رشتۀ اول، تخصیص حافظه را انجام دهد، رشتۀ دوم در جایی که هنوز رزرو نشده بنویسد.
باز هم هر راهکاری برای این مسئله مطرح کنید، سربار اضافی دارد. واقعاً ما در متغیرهای محلی و مانند آن، اصلاً دچار چنین معضلاتی نیستیم تا بخواهیم راهکاری برایش بیابیم؛ تابعی که ورودی مشخصی دارد، عمل مشخصی انجام میدهد و خروجی مشخصی نیز برمیگرداند و هیچ اثر جانبی هم ندارد، اصلاً نیازی به این پیچیدگیها ندارد؛ پیچیدگیهایی که هم عملکرد را تحتتأثیر قرار میدهند و هم برنامهنویسی را ممکن است سختتر کنند.
حافظۀ Heap
در این زمان نیازمند نوعی دیگر از مدیریت حافظه هستیم که شرایط پیشگفته را نیز بتواند مدیریت نماید، حتی اگر کارایی کمتری را فراهم آورد. این همان حافظۀ Heap است. خوبی حافظۀ Heap این است که میتوانیم مواردی که کارایی اهمیت بیشتری دارد را از مواردی که صحت عملکرد برنامه اهمیت بیشتری دارد، جدا کنیم. برای مثال شیوۀ سادۀ Stack را برای متغیرهای محلی و زنجیرۀ توابع استفاده میکنیم، و شیوۀ Heap را برای جاهایی که Stack بهخوبی جواب نمیدهد؛ یا موجب عدم اختصاص صحیح حافظه میشود، یا با دادهای سروکار داریم که بین Threadهای مختلف مشترک است.
توضیح عملکرد Heap
متغیرهایی که در حافظۀ Heap ذخیره میشوند طولشان در زمان کامپایل مشخص نیست. بلکه بهتناسب شرایط مختلف، طول متفاوتی دارند. مثلاً در زمان تعریف متغیر و اختصاص حافظه به آن، یک طول اولیه به متغیر تخصیص داده میشود، و آنگاه اگر دادۀ ورودی از آن قسمت بیرون میزد، طول آن گسترش داده میشود. اگر جا برای گسترش نبود و مثلاً دادۀ دیگری در همسایگی نزدیک آن بخش از حافظه وجود داشت، قسمتی دیگر از حافظه برای دنبالۀ آن متغیر پیدا میشود؛ حتی ممکن است کل دادۀ قبلی به همراه بخش اضافۀ آن، منتقل شوند به نقطۀ دیگری از حافظه که فضای مناسب برای مجموع آن را داشته باشد.
مسئلۀ دیگری که Heap به آن میپردازد، امکان دسترسی چند رشتۀ پردازشی به دادۀ مشترک است. دادههای درون Heap چون مرتبط با جریان دستوراتی که درون یک رشتۀ پردازشی اجرا میشوند نیستند، اساسا امنیت حافظه در آنها مطرح نیست و کاملا ناامن هستند. به همین خاطر است که برنامهنویسی همزمان، یکی از چالشهای اصلی طراحی نرمافزار است و هر زبان برنامهنویسی راهکاری را برای این معضل ارائه کرده است. اما در Stack از آنجا که دادهها به هر Thread پیوند خوردهاند و میان Threadها مشترک نیستند، امن هستند و نیازی به رفع این چالشها نیست. در نتیجه ساز و کار Stack درعین سادگی بخشی از مشکلات ما را حل میکند، ولی Heap پیچیدگیهای خود را صرفا در جایی به ما تحمیل میکند که واقعا به این پیچیدگی نیاز باشد.
ویژگیها و محدودیتهای Heap
در نتیجه Heap چند ویژگی دارد:
- حجم هر متغیری که درون آن قرار میگیرد در هنگام کامپایل و تخصیص حافظه مشخص نیست.
- دادههای مربوط به یک متغیر ممکن است در نقاط مختلفی از حافظه پخش شوند.
- امنیت در دسترسی مشترک دو رشتۀ پردازشی به اطلاعات درون Heap وجود ندارد و در این مسئله محتاج روشهایی هستیم تا آن را بتوان مدیریت نمود.
- ازآنجاکه هیچ رشتۀ پردازشی نمیداند چه زمانی باید حافظۀ درون Heap را آزاد کند (چراکه مختص به آن رشته نیست)، احتمال اینکه حافظه پر شود از دادههایی که دیگر به آنها نیازی نیست، وجود دارد. این مسئله مخاطرات امنیتی متفاوتی نیز ایجاد میکند؛ همچون حذف مجدد یک داده، پرشدن حافظه و… .
- همواره نیازمند روشی برای پاکسازی حافظه هستیم؛ یا بهصورت دستی توسط خود برنامهنویس (نظیر آنچه در C++ میبینیم) یا بهصورت خودکار توسط Garbage Collector (نظیر آنچه در جاوا شاهد آن هستیم) یا با سازوکار اختصاصی زبان Rust.
- سرعت کمتر نسبت به Stack؛ سیستم مجبور است محاسبات بیشتری برای پیداکردن دادۀ ما در درون حافظه انجام دهد.
تفاوتهای Stack و Heap
در نتیجه در تفاوت Stack و Heap میتوان چنین گفت که این دو، دو راهکار استفاده از حافظه هستند. آنجایی که نیازمند به متغیرهایی هستیم که بهصورت امن در بین دستورات پیاپی و متوالی دست به دست میشوند و حجمشان نیز مشخص است (معمولا در متغیرهای کنترلی و موقتی که برای پیادهسازی الگوریتمها و فراخوانی توابع استفاده میشوند)، از روش Stack استفاده میکنیم. اما در جایی که نیازمند به دادهای هستیم که رشتههای پردازشی مختلف میتوانند مشترکا به آن دسترسی داشته باشند، یا اینکه حجم داده مشخص نیست (ولو در رشتۀ پردازشی واحد)، از روش Heap استفاده میکنیم.
برای اطلاعات بیشتر از مسئلۀ مدیریت حافظه، به مباحث مربوطه در درس «سیستمهای عامل» مراجعه فرمایید.
فضای rodata یا read-only data
فضای سومی هم وجود دارد که غیر از Heap و Stack است با نام rodata. این فضا محل استقرار برخی دادههای خاص است همچون ثوابت (Consts) و String Literals. دادههای موجود در این فضا همگی درون فایل باینری برنامه قرار میگیرند (کامپایلر این کار را بهصورت خودکار انجام میدهد).
این دادهها همیشه در درون برنامه در دسترس هستند و هرگز هم نابود نمیشوند. نه مشکل حجم داده را دارند و نه مشکل دسترسی همزمان چند Thread را. حتی وابستگی به ترتیب اجرای کد نیز ندارند و هر زمان که به آنها نیاز داشتیم از آنها استفاده میکنیم، ولی قابل تغییر نیستند.
مدیریت Stack و Heap در Rust
در Rust روشی اختصاصی برای مدیریت Stack و Heap وجود دارد که نقطۀ اساسی تمایز این زبان با سایر زبانها است. از طرفی مدیریت آن به نحو دستی نیست، و از طرفی بهصورت خودکار توسط GC نیست. در نتیجه نه سختی کار با C++ را دارد و نه کاهش کارایی جاوا را. این روش همان قوانین Ownership و Borrowing یا مالکیت و قرضدادن است که برنامهنویس را مجبور میکند تا از ابتدا کدی امن بنویسد بهطوریکه اصلاً نشتی حافظه رخ ندهد و دسترسیهای چند رشته به دادۀ واحد نیز بهخوبی مدیریت شود.
زبان Rust ازاینجهت اگرچه در ظاهر سختتر از زبانی همچون جاوا مینماید، اما در پروژههای متوسط به بزرگ، این مسئله چندان به چشم نمیآید.
خلاصه
در این مقاله با Stack و Heap آشنایی نسبتا عمیقی پیدا کردیم و تفاوتهای میان آنها را دریافتیم. سپس به معرفی سازوکار زبان برنامهنویسی Rust در مدیریت آن آگاه شدیم و دانستیم که Rust نه از طرق مرسوم، بلکه با روش اختصاصی خود که به مالکیت و قرضدادن معروف است، با این دو نحوۀ مدیریت حافظه مواجه میشود.